
本博客曾换过多次域名以及建站工具,从 Wordpress 到 Halo 1.x,最近升级到 Halo2.x。最初网站挂载在腾讯云上,但是考虑到内容安全,最后决定放置在本地。为了提升网站的访问速度,决定给博客添加一个ipv6的域名地址,这样就不用经过服务器的中转。本文的前提是,halo博客通过docker运行在群晖中,群晖具有ipv6。
一、申请证书
进入DNSPod的控制台:https://console.dnspod.cn/ ,可以查看到目前绑定在腾讯云上的域名,点击SSL:
二、给群晖添加证书
进入控制面板-> 安全 -> 证书中,点击新增 -> 新增证书 -> 导入证书:
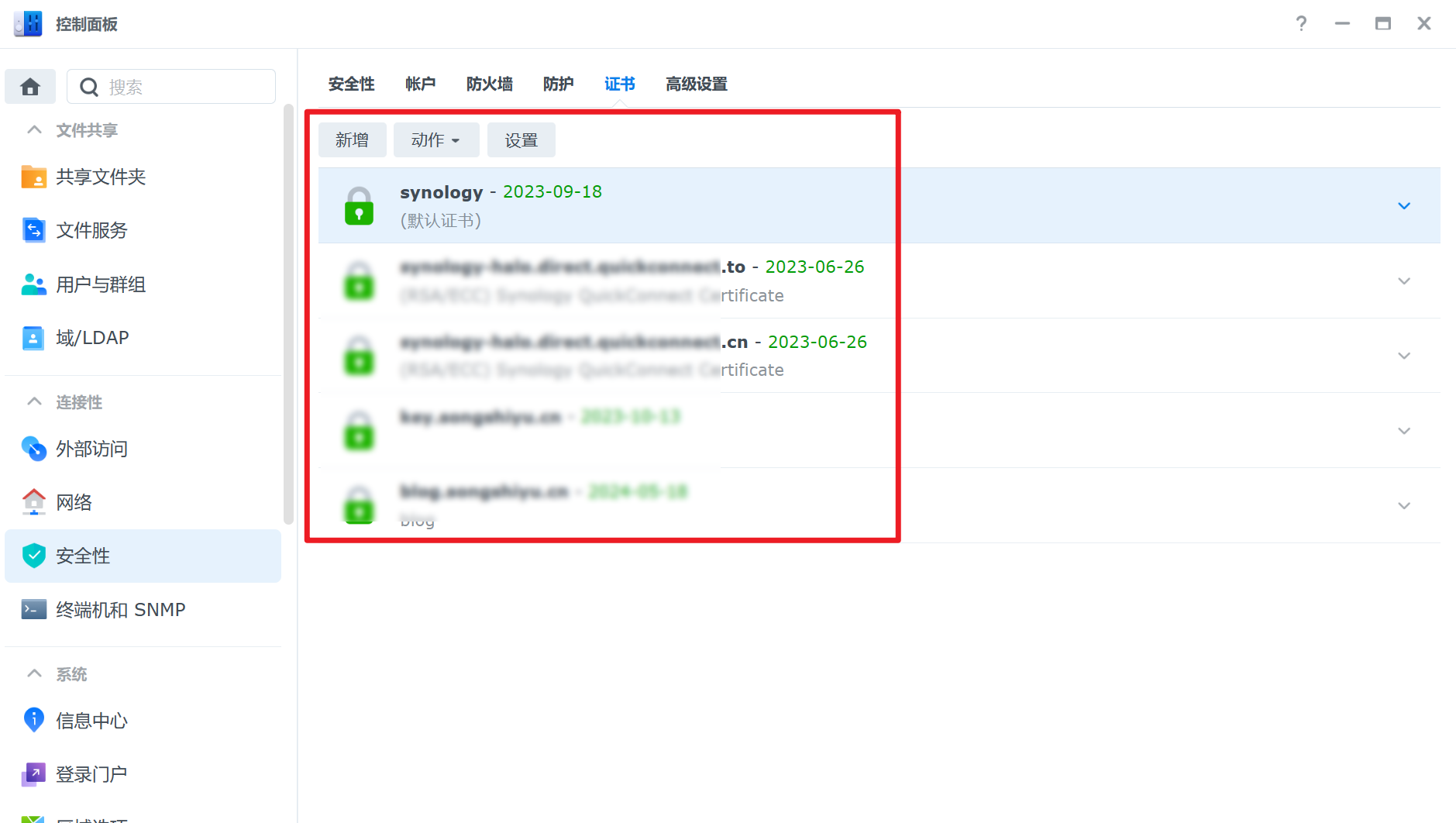
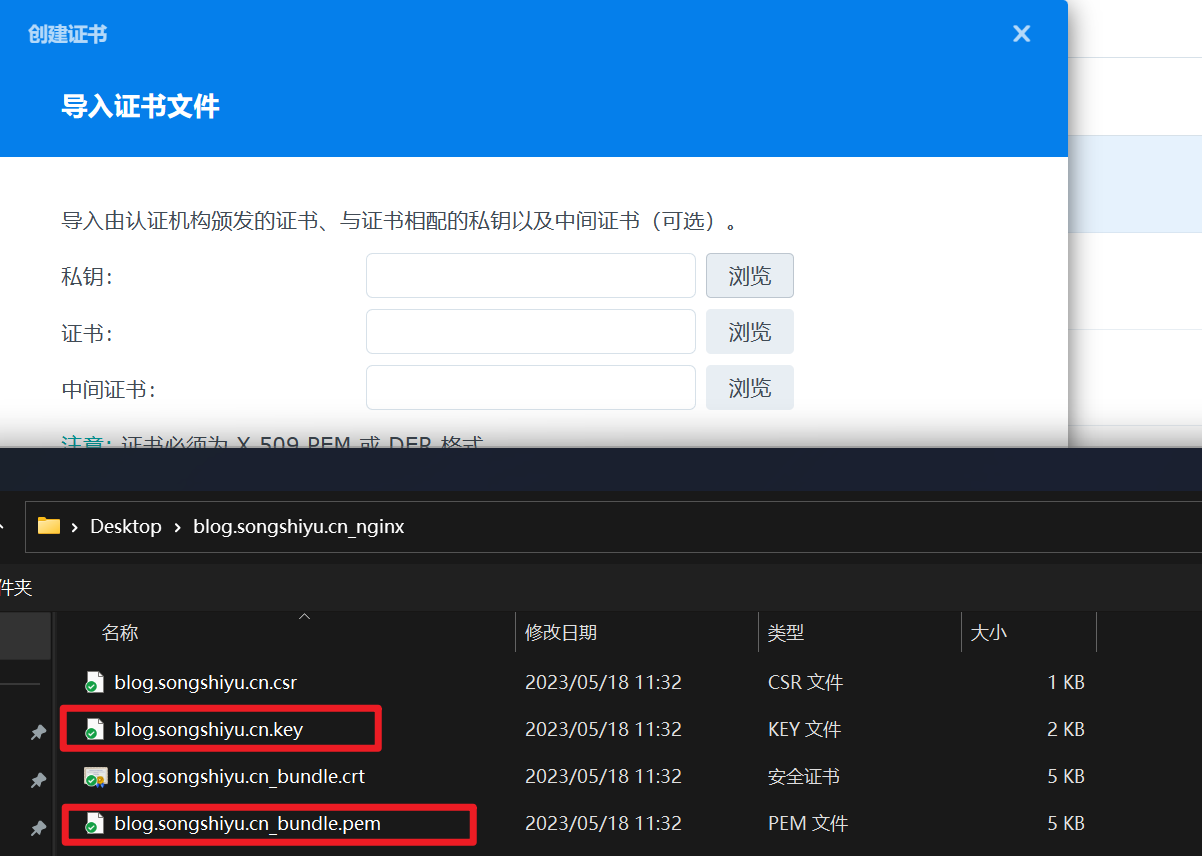
密钥上传 xxx.key 文件
证书上传 xxx.pem 文件
然后在设置中,将证书和域名对应。

三、在群晖中设置反向代理
家宽ipv6的 80和443 端口好像都没有封掉,我们首先将博客的域名解析在群晖上,这样直接访问 blog.songshiyu.cn 可以访问到群晖的登录界面。这里可以使用DDNS,详情见:
点击控制面板 -> 登录门户 -> 高级 -> 反向代理服务器 -> 新增:
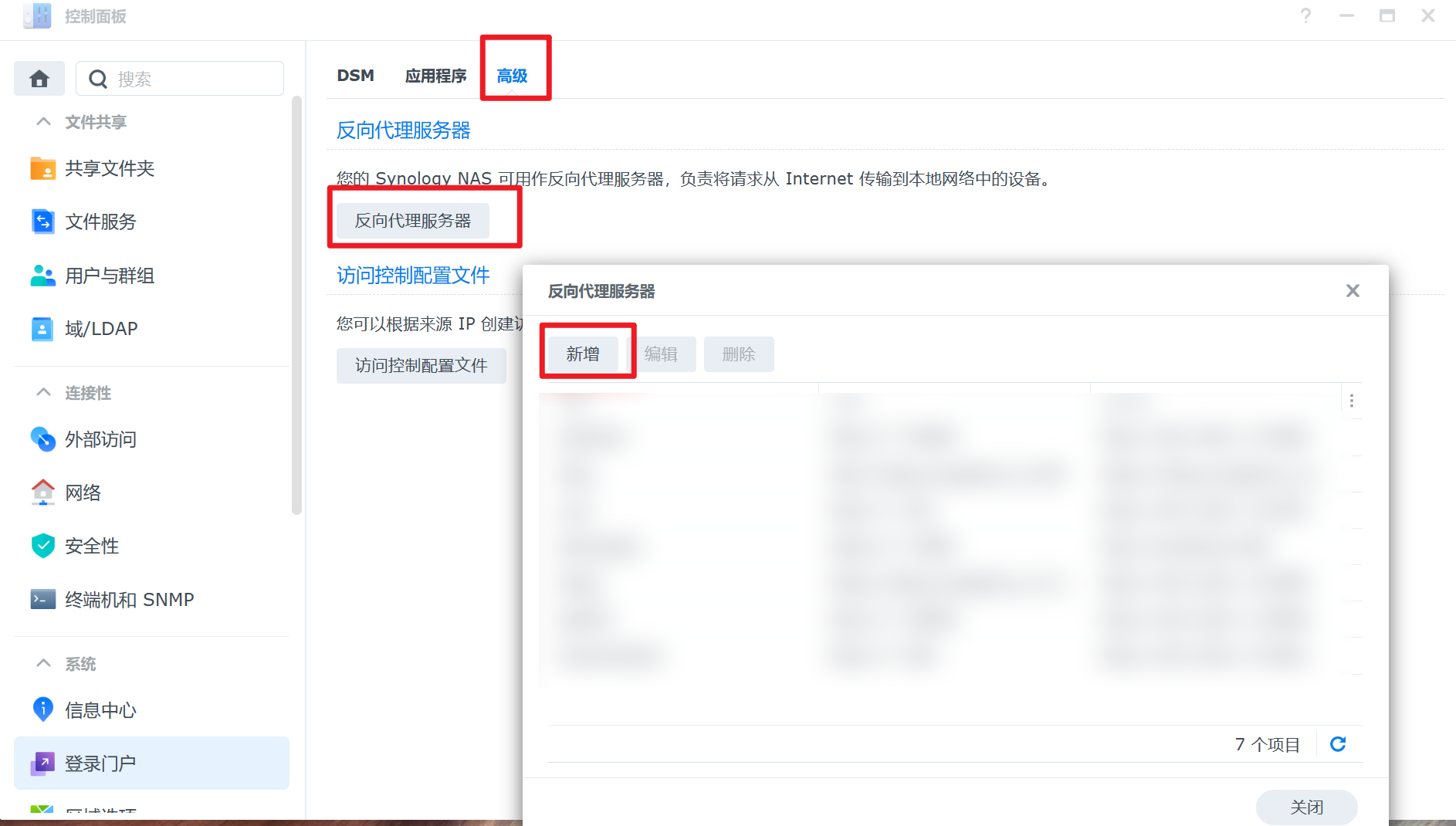 新增两个规则:
新增两个规则:
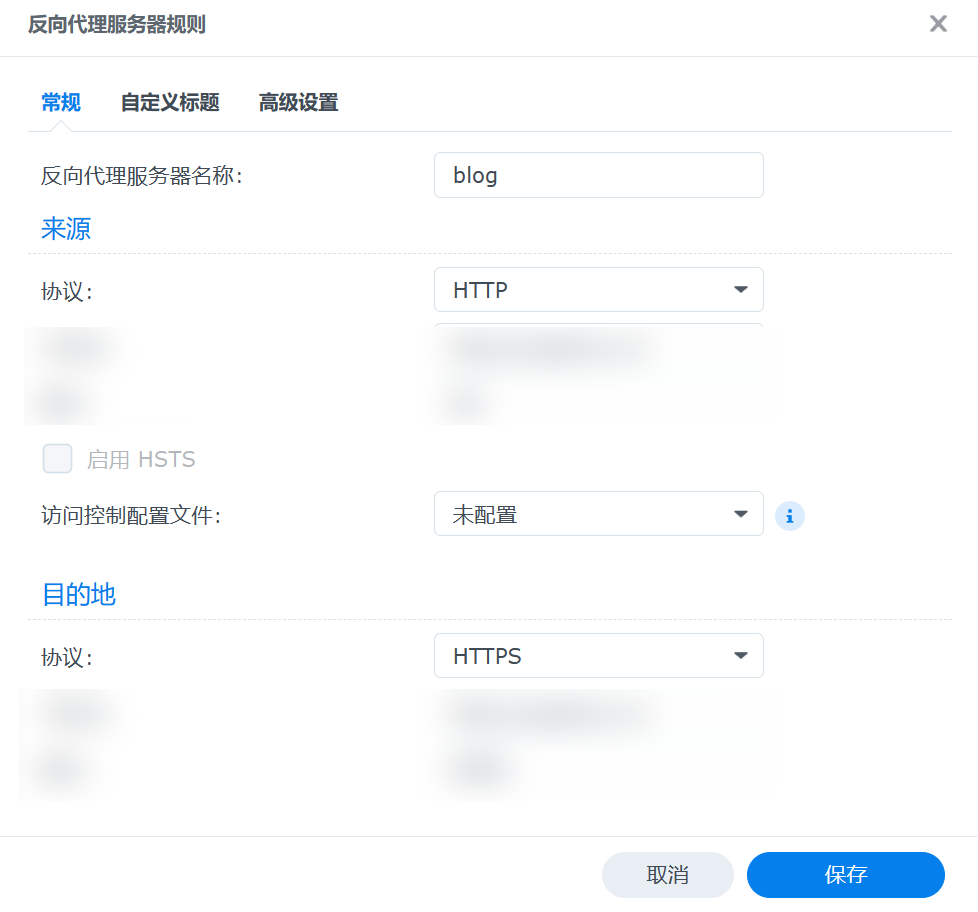 主机名填写域名 blog.songshiyu.cn
主机名填写域名 blog.songshiyu.cn
端口填写80
下面的主机名填写域名 blog.songshiyu.cn
端口填写443
主机名填写域名 blog.songshiyu.cn
端口填写443
下面的主机名填写本地ip
端口填写Halo博客的端口
这样的意思就是,当输入http://blog.songshiyu.cn 的时候,转跳到 https://blog.songshiyu.cn 。当输入 https://blog.songshiyu.cn 的时候,访问Halo的端口。